\(\color{steelblue}{p(\mathbf{y}| M_\gamma)}= \int p(\mathbf{y} | M_\gamma, \boldsymbol{\theta}_\gamma) p(\boldsymbol{\theta}_\gamma|M_\gamma) d\boldsymbol{\theta}_\gamma\) is the marginal likelihood of the data for the model \(M_\gamma\) (marginalized over the entire parameter space).
How do we choose among the \(2^P\) models?
By balancing model fit and model complexity (trade-off): \[\text{Score} = \text{Fit} - \text{Complexity}\]
Fit: Marginal probability of data given model \(\color{steelblue}{p(\mathbf{y} | M_\gamma)}\)
Complexity: Prior probability of model \(\color{orange}{p(M_\gamma)}\)
Unlike the maximized likelihood, the marginal likelihood has an implicit penalty for model complexity.
The highest posterior probability model (HPM) is then the model with the highest marginal likelihood.
Selection Criteria
Bayes Factor
Bayes factor (BF) can be used to compare and choose between candidate models, where each candidate model corresponds to a hypothesis.
Unlike frequentist hypothesis testing methods, Bayes factors do not require the models to be nested.
The BF for model \(M_{1}\) over \(M_2\) is the ratio of posterior to prior odds:
\[ BF_{12} = \frac{p(y | M_1)}{p(y | M_2)} \]
Interpretation:
Values of \(BF_{12} >1\) suggest \(M_1\) is preferred.
The larger \(BF_{12}\) is, the stronger the evidence in favor of \(M_1\).
Correlation: Look at how \(\gamma_p\) is corelated with \(\gamma_q\).
Markov chain Monte Carlo (MCMC)
When p is small (P<20), exhaustive search of all candidate models and computation of posterior probabilities is feasible.
When p is large, MCMC methods are commonly implemented to perform a stochastic search of model space and allows efficient samping from posterior distribution of parameters.
For example,
Reversible-jump MCMC allows the Markov chain to explore the parameter space of different dimensions.
Gibbs sampling based on pseudo-priors can facilitate chain jumping between competing models.
Bayesian Approach to Variable Selection
2. Spike and Slab Priors
The spike-and-slab prior is a two-point mixture distribution on \(\beta_j\): \[\beta_j\sim (1 - \gamma_j)\color{steelblue}{\phi_0(\beta_j)} + \gamma_j\color{orange}{\phi_1(\beta_j)}\]
\(\tau_j\): Small for spike to cluster \(\beta_j\) around zero when \(\gamma_j = 0\).
\(c_j\): Large for slab to disperse \(\beta_j\) when \(\gamma_j = 1\).
Facilitates efficient Gibbs sampling for posterior computation:
Assign initial values for \(\beta^{(0)}, \sigma^{2(0)}, \gamma^{(0)}\).
Sample \(\beta^{(1)}\) from \(f(\beta^{(1)} | y, \gamma^{(0)}, \sigma^{2(0)})\).
Sample \(\sigma^{2(1)}\) from \(f(\sigma^{2(1)} | y, \beta^{(1)}, \gamma^{(0)}))\).
Sample vector \(\gamma^{(1)}\) componentwise from \(f(\gamma_i^{(1)} | \beta^{(1)},\sigma^{2(1)}, \gamma_{(i)}^{(1)})\).
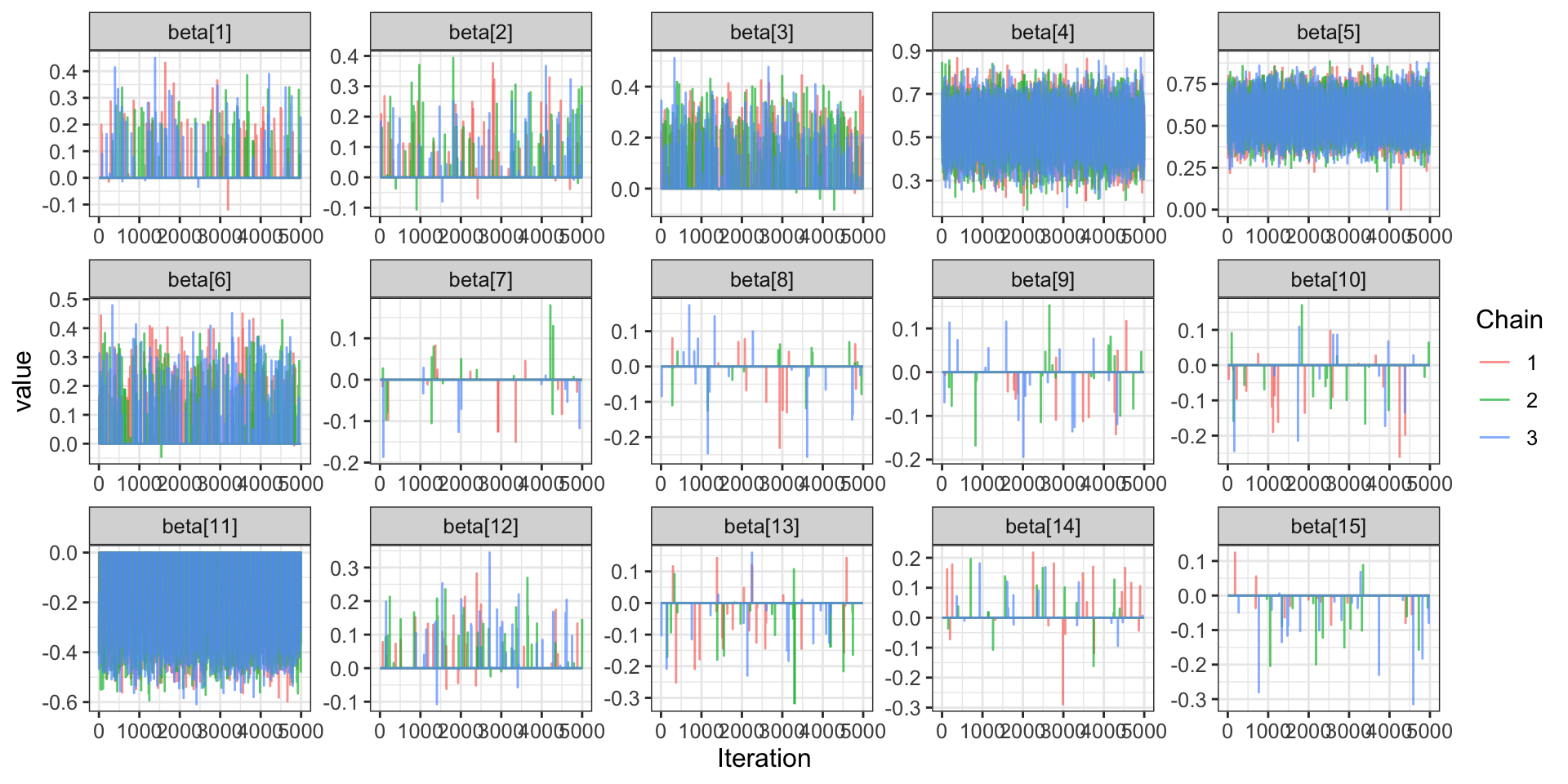
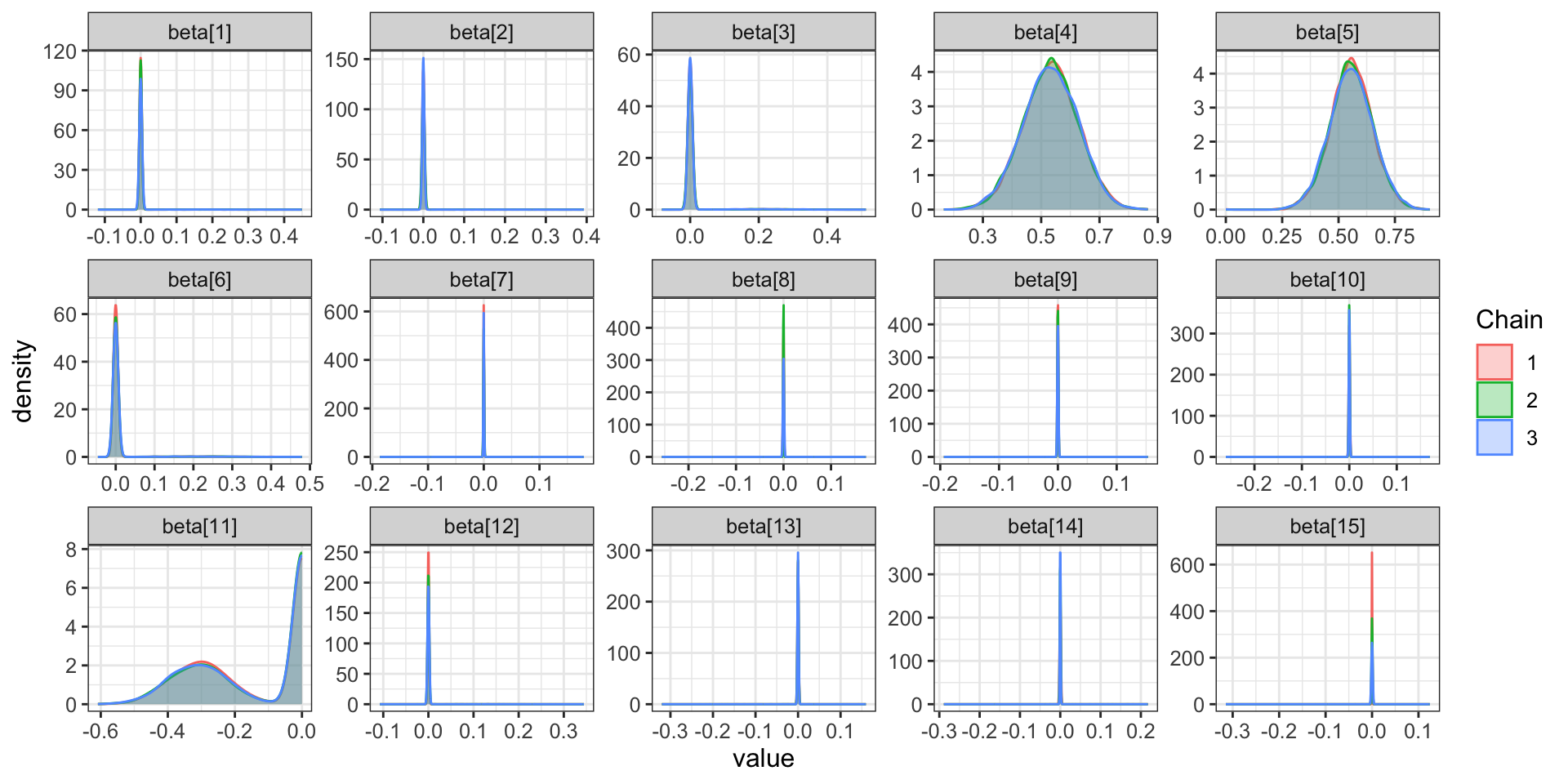
Continue the process until convergence to form a Markov chain - Gibbs sequence.
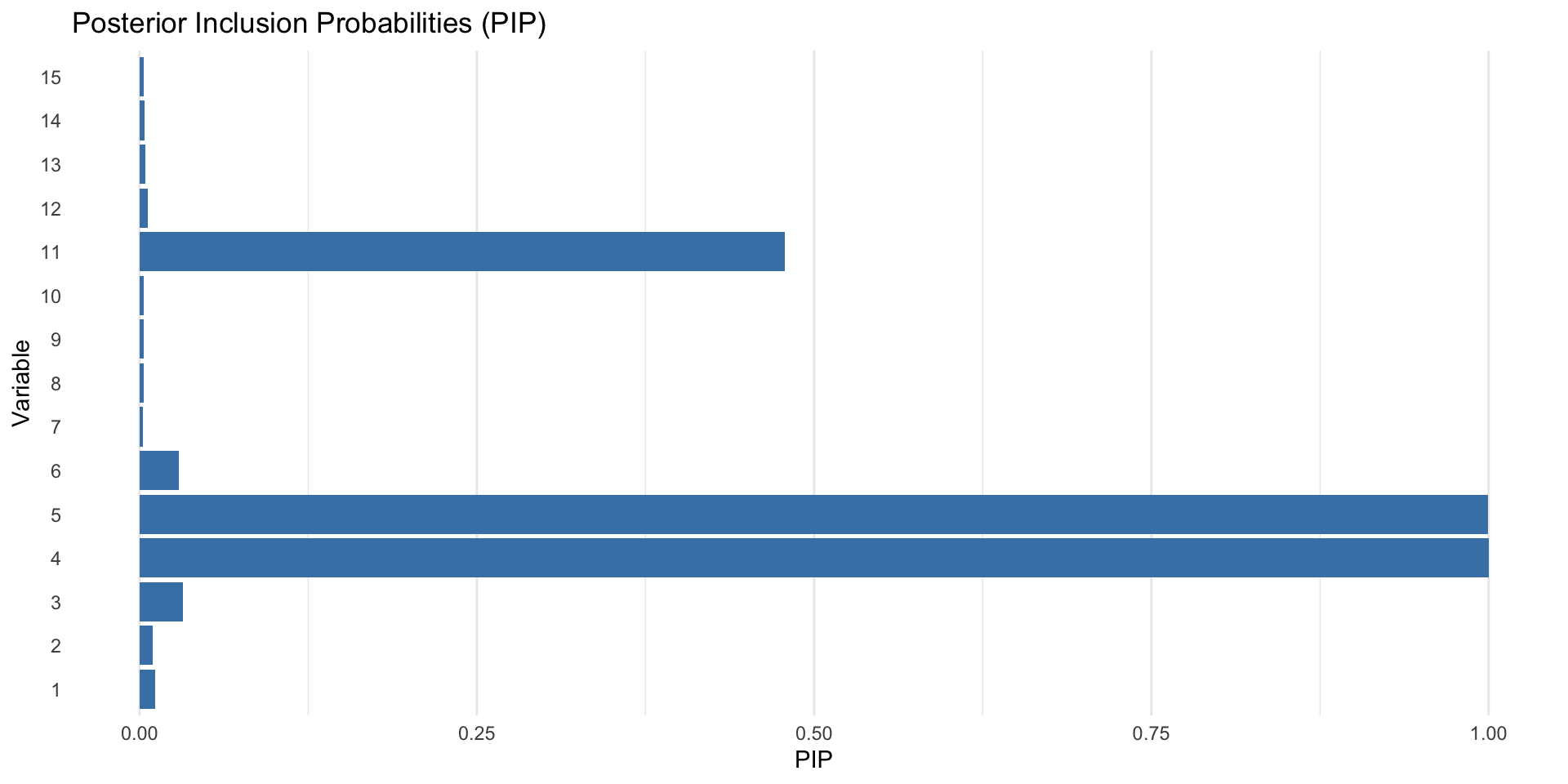
The densities of the spike and slab intersect at points \(\pm \xi_j\), \(\xi_j = \tau_j \sqrt{2 \log(c_j) \frac{c_j^2}{c_j^2 - 1}}\), serving as practical significance thresholds for \(\beta_j\).
Bayesian Approach to Variable Selection
3. Continuous Shrinkage Priors
Idea: place a prior on the coefficients \(\boldsymbol{\beta}\) that concentrates near zero
Mimics the spike-and-slab prior by a single continuous density.
The \(\color{steelblue}{\tau} \rightarrow\) the global shrinkage parameter (i.e. controlling the shrinkage of all coefficients).
The \(\color{orange}{\lambda_j} \rightarrow\) local shrinkage parameter (i.e. controlling the shrinkage of a specific coefficient)
\(\text{Ca}^+(0,1)\) is a half-Cauchy distribution for the standard deviation \(\lambda_j\).
Key advantages: Adaptability and Robustness
Hamiltonian MCMC
Others: Normal-gamma, Dirichlet-Laplace,…
Applications
Implementation in Nimble
Simulate Data
library(nimble)library(magrittr)library(ggplot2)library(coda) # for summarizing and plotting of MCMC output and diagnostic testslibrary(ggmcmc) # MCMC diagnostics with ggplot# data ########################################################################N <-100p <-15set.seed(123)X <-matrix(rnorm(N*p), nrow = N, ncol = p)true_betas <-c(c(0.1, 0.2, 0.3, 0.4, 0.5),rep(0, 10))y <-rnorm(N, X%*%true_betas, sd =1)# standard linear regression ##################################################summary(lm(y ~ X))
O’Hara RB, Sillanpää MJ. A review of Bayesian variable selection methods: what, how and which. Bayesian Analysis. 2009;4(1):85-117. doi:10.1214/09-BA403
George EI, McCulloch RE. Approaches for Bayesian Variable Selection. Statistica Sinica. 1997;7(2):339-373.
Carlin BP, Chib S. Bayesian Model Choice Via Markov Chain Monte Carlo Methods. Journal of the Royal Statistical Society: Series B (Methodological). 1995;57(3):473-484. doi:10.1111/j.2517-6161.1995.tb02042.x
Tang X, Xu X, Ghosh M, Ghosh P. Bayesian Variable Selection and Estimation Based on Global-Local Shrinkage Priors. Sankhya A. 2016;80. doi:10.1007/s13171-017-0118-2
García-Donato G, Castellanos ME, Quirós A. Bayesian Variable Selection with Applications in Health Sciences. Mathematics. 2021;9(3):218. doi:10.3390/math9030218
Dellaportas P, Forster JJ, Ntzoufras I. On Bayesian model and variable selection using MCMC. Statistics and Computing. 2002;12(1):27-36. doi:10.1023/A:1013164120801
Boehm Vock LF, Reich BJ, Fuentes M, Dominici F. Spatial variable selection methods for investigating acute health effects of fine particulate matter components. Biometrics. 2015;71(1):167-177. doi:10.1111/biom.12254
Hu G. Spatially varying sparsity in dynamic regression models. Econometrics and Statistics. 2021;17:23-34. doi:10.1016/j.ecosta.2020.08.002
Regresssion I, Geweke J. Variable Selection and Model Comparison in Regresssion. Bayesian Statistics. 1995;5.
Kuo L, Mallick B. Variable Selection for Regression Models. Sankhyā: The Indian Journal of Statistics, Series B (1960-2002). 1998;60(1):65-81.
George EI, McCulloch RE. Variable Selection via Gibbs Sampling. Journal of the American Statistical Association. 1993;88(423):881-889. doi:10.1080/01621459.1993.10476353